At RJMetrics, we have always wanted to provide our customers the ability to push data from a variety of platforms into our system, at any time, no questions asked. After months of hard work, we finally opened up our Data Import API to our customer base this July, allowing RJMetrics to accept data from many more sources. So far, our customers have pushed data from over a dozen platforms, including Shopify and Magento.
In this post, I’ll talk about the development of this API, from the original idea to its current form, and hopefully uncover some interesting insights along the way.
MVP: Hackathon Project
When the first RJMetrics hackathon rolled around last fall, Yiannis, Cathy and I teamed up to build a MVP of the Import API. The design was loose: we knew we wanted to create a web endpoint that would accept arbitrary JSON data and pull it into our data warehouse. After 24 hours of hacking and a few too many Red Bulls, we had a working prototype. The original code was written in PHP as part of our main repository, authenticated the request with a pre-generated API key, and inserted the incoming data into a MongoDB table. From MongoDB, we would then pull the incoming data into our data warehouse using our MongoDB replicator.
As with any hackathon project, this API had its fair share of shortcomings: it was slow, sloppy and totally unscalable. Over the next few months we worked to hash out a new and improved design for the Import API.
Performance Concerns and Node.js
As we were planning the next iteration, we had a hunch that we could build a faster API if we ditched Apache and PHP. We decided that we wanted to create an apples-to-apples comparison of the API written in two languages. Node.js seemed like a logical choice, since we desired reasonable resource usage per request, and non-blocking IO. So, over the course of a couple of weeks, we rewrote the API as a Node.js app with an identical algorithm, and moved both versions onto EC2 for testing.
Then we used a Linux tool called Siege to load test the two APIs, and the results were staggering: on the same EC2 instance size, our Node.js API could process, validate and hand off _just over forty times_ the volume of data that the PHP API could handle, with a bursty data stream composed of JSON data points of varying size.
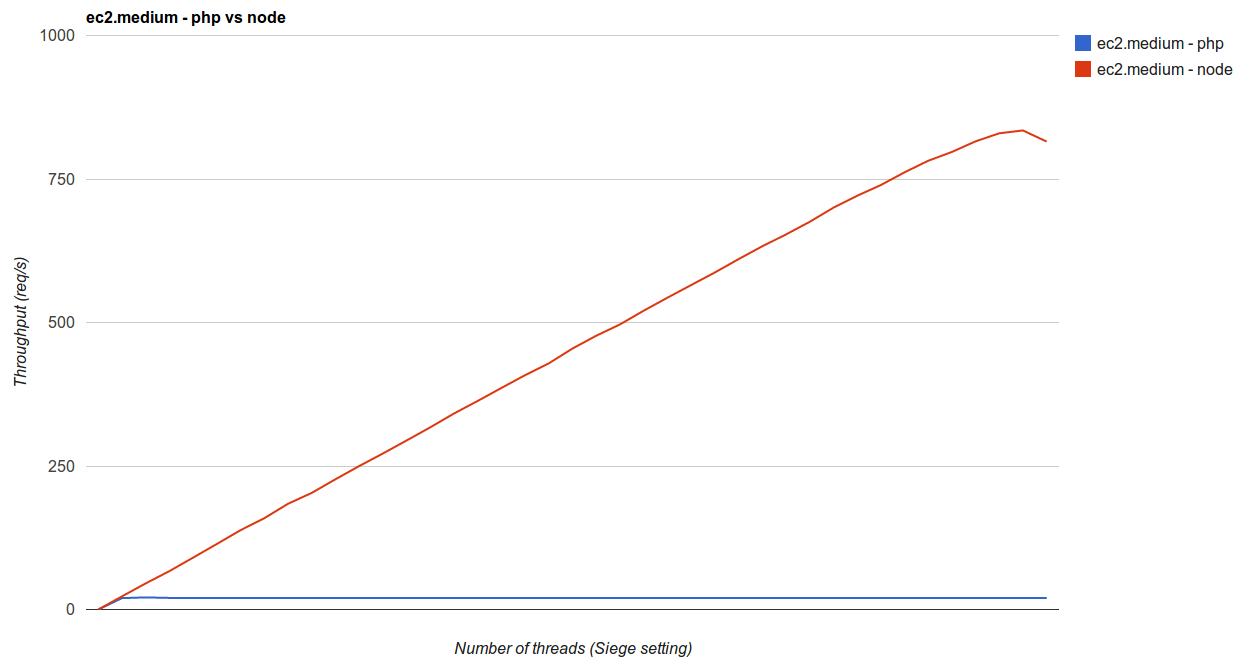
We expected Node.js to be faster, but this result was so insane that we had to explore further. What we found was that with each incremental request, Apache used more and more CPU, and gradually slowed down. At around 20 sustained requests per second, Apache was using 100% CPU and nearly 100% memory, and started to drop requests.
Our Node.js server, on the other hand, used a consistent amount of memory and only reached 100% CPU utilization at just over 800 sustained requests per second.
Looking at the response times between the two, Node.js was the clear winner:
| Number of request threads (Siege) | PHP | Node.js | ||
|---|---|---|---|---|
| Mean Response Time (s) | Throughput (req/s) | Mean Response Time (s) | Throughput (req/s) | |
| 5 | 0.07 | 4.65 | 0.22 | 4.41 |
| 10 | 0.06 | 9.77 | 0.15 | 8.93 |
| 20 | 0.26 | 17.54 | 0.14 | 18.64 |
| 100 | 7.2 | 20.02 | 0.15 | 90.46 |
| 600 | N/A | N/A | 0.17 | 543.11 |
The Node API’s mean response time stayed remarkably stable even at a very high level of throughput, while PHP/Apache almost immediately began to slow down.
With these results in hand, there was no decision to be made – Node.js crushed PHP in every category. We quickly pulled the plug on the PHP API in favor of the Node.js version.
Version 1.0
As part of our design, we knew that we wanted to be able to scale the API both up and down. For us, that meant each instance running this API had to be totally stateless. Additionally, we wanted to automate the process of scaling up and down. We started to design a cluster of machines where:
– All credentials would be stored remotely (we decided to use a multi-AZ, replicated RDS cluster)
– The instances would run behind a load balancing proxy (we use ELB)
So, we built out a simple model on EC2 with the image we had generated before, and began another round of throughput testing. When profiling the new API, we found that validating credentials with the DB was taking up nearly half of the total mean request time. We decided to implement simple caching to alleviate the slowdown.
Our original key validation logic looked like this:
coffee
get_key = (key_string) ->
deferred = Q.defer()
connection.query(“SELECT rights FROM apikeys WHERE key_string = " + escape(key_string), (error, rows) ->
if(error)
deferred.reject(error)
else
if(rows.length)
return deferred.resolve(rows[0])
deferred.reject()
)
return deferred.promise
Now, we wanted to create a time-based cache in Node.js. All we had to do was use a setTimeout to invalidate each entry after one hour. The code became:
coffee
get_key_from_cache = (key_string) ->
if cache.hasOwnProperty(key_string)
return cache[key_string]
return null
add_key_to_cache = (key_string, rights) ->
cache[key_string] = rights
setTimeout( () ->
delete cache[key_string]
, (60 * 60 * 1000) )
get_key = (key_string) ->
deferred = Q.defer()
cache_value = get_key_from_cache(key_string)
if cache_value
deferred.resolve(cache_value)
connection.query(“SELECT rights FROM apikeys WHERE key_string = " + escape(key_string), (error, rows) ->
if(error)
deferred.reject(error)
else
if(rows.length)
add_to_key_cache(key_string, rows[0])
return deferred.resolve(get_from_key_cache(key_string))
deferred.reject()
)
return deferred.promise
With about a dozen lines of code, this improved the mean response time of each server by a factor of nearly 2.
Lessons Learned
Bad code becomes good code
Our initial version was clunky, slow, difficult to read and poorly designed. But, because it worked, a lot of people started to get really excited about the project. Because of all that excitement, the team was able to step back and take a more holistic approach, and we ended up with something really awesome. 100% of the code from that first hackathon has been discarded, but the idea and excitement are still there. Write something that solves the problem at hand, even if it’s messy. If it works well, you’ll gain a lot of momentum to make it better.
Simplicity is key
Solving hard problems is very time-consuming. Lots of thought and attention need to go into tiny (but important) details. However, hard problems are typically a composition of a bunch of smaller problems, so start small. Don’t worry about security, scalability, and performance right off the bat. Build something that works, and then work your way into the details as you get a better understanding of the problem space. That way, you’ll get buy-in from others right away, while building something awesome in a very incremental way.
Experiment early and often
At the outset, we had a theory that network I/O between machines would become a bottleneck for the API. As soon as we had a simple API working we began to test everything, including CPU usage, memory usage, and bandwidth. Once we had some hard data to look at, we dismissed that notion, and instead focused on two small changes (rewrite in Node and caching) that improved our throughput by a factor of 50. Experiment from the outset so you spend more time on big wins and less time on problems that don’t actually exist.
We’re excited to keep developing this API both as a technology and as a platform for getting data into RJMetrics. Stay tuned for more news on all of the new data sources that we’ll support over the coming months!