Subscribe here to receive the Data Science Roundup every Sunday morning.
Science Isn’t Broken. It’s Just Really Hard.
Science Isn’t Broken | FiveThirtyEight
In a widely discussed article, Christie Aschwanden, lead writer for science at FiveThirtyEight, details a crisis of confidence that is currently roiling through the scientific community. Aschwanden believes the crisis is fueled by a broken incentive system that currently doesn’t align with our need to rely “on science as a means for reaching the truth.”
The article sheds light on a concerning technique of data manipulation known as “p-hacking.” Aschwanden goes deeper on the topic on the What’s the Point podcast. Rather than calling for an end to p-hacking, her recommendation is more of it…just paired with increased transparency:
We shouldn’t think of p-hacking as this terrible thing that’s cheating. We should actually make it compulsory…tell us every single variable that you collected, every way that you analyzed it and don’t just give us the one thing that you got a good p-value for…seeing [variations] in context of the other analyses, it really gets us a lot closer to truth, and remember, that’s what we’re supposed to be going after.
Aschwanden’s investigation leads her to conclude that science is far from broken, but that variations in results occur precisely because the “scientific method is the most rigorous path to knowledge,” and as long as practitioners continue to embrace this fact, science will garner the respect it deserves.
 Tweet This
Tweet ThisWhich Type of Data Scientist Are You?
Doing Data Science at Twitter | Medium
Data Scientist, Robert Chang, shares a reflection on his two years working as a data scientist at Twitter, and why it’s useful for an aspiring data scientist to keep in mind the distinction between two types of data scientists: Type A (for Analysis) vs. Type B (for Building).
Chang was inspired to write the post out of a concern for how popular articles on learning how to become a data scientist (which he does not diminish, and admits to benefiting from) can often put too much emphasis on “techniques, tools, and skill-sets,” while shedding less insight on what data science looks like “in practice.”
The post includes Chang’s description of recent changes in data science at Twitter, how these changes impacted his role, and what skills he needed to use to adapt. It’s a must read for aspiring data scientists.

Got Social Skills?
Research: Technology Is Only Making Social Skills More Important | HBR
Nicole Torres reports on a paper published by the National Bureau of Economic Research (NBER) that found a growing importance for social skills in the labor market. Why? David Demming, associate professor at the Harvard Graduate School of Education, offers two reasons in the paper:
- computers still can’t simulate social interaction
- flexibility in playing off the strengths of fellow team members and adapting to change is increasingly significant.
Demming’s research can essentially be boiled down to these two charts:
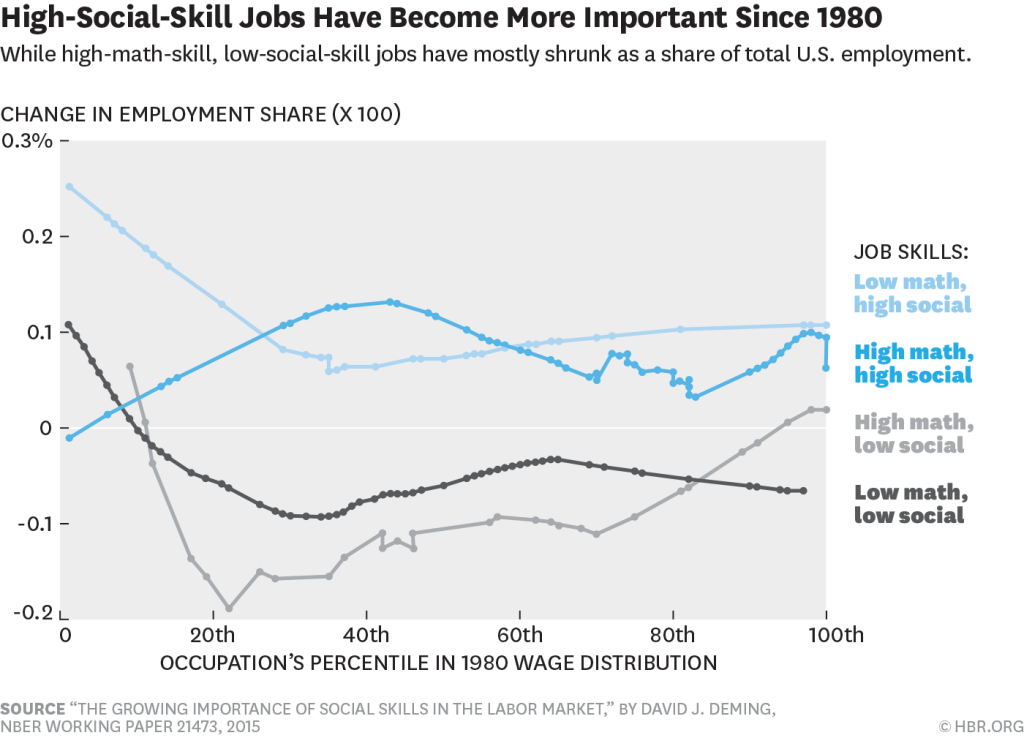
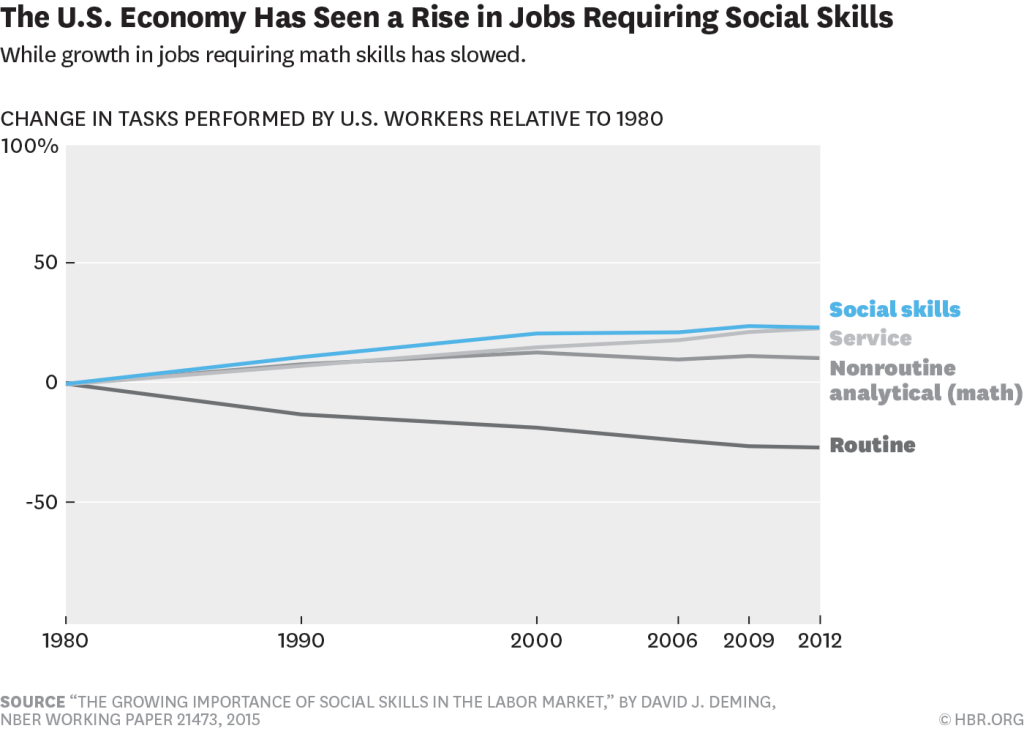
While the job market has always looked favorably on those with both math and people skills, the balances have never been tipped so greatly in the favor of this unique (and valuable) blend.
Meet the Man Who Revolutionized R
Hadley Wickham, the Man Who Revolutionized R | Priceonomics
Dan Kopf of Priceonomics shares the story of Hadley Wickham, the statistician from New Zealand who has become a “giant among data nerds” because of the programming packages he has created for the open-source statistical programming language R. His packages are used by tech giants like Google and Facebook, media outlets like the New York Times and FiveThirtyEight, and government agencies like the FDA and DEA.
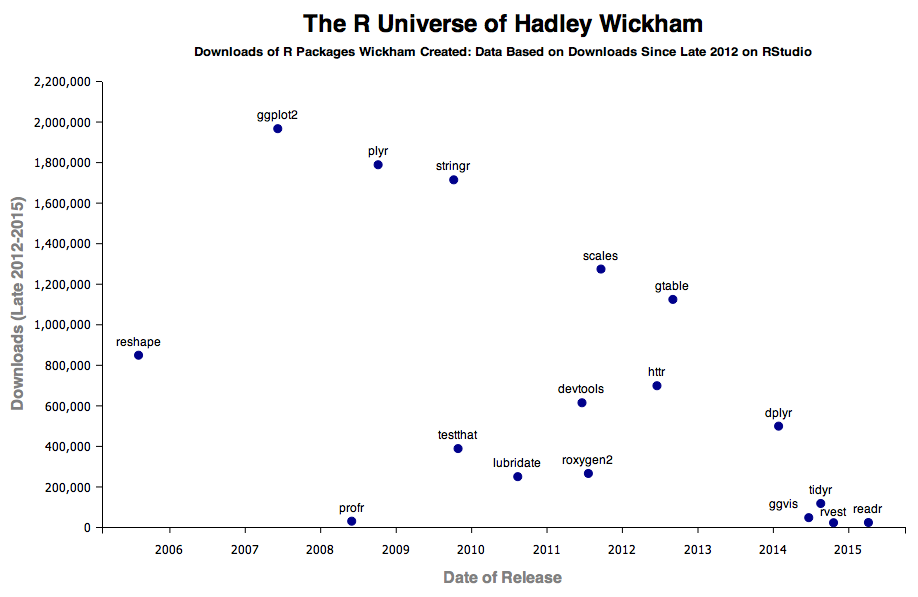
Wickham shares how his motivation for empowering people who like to play with data, combined with the fact that he is “exquisitely sensitive to frustration,” has fueled his creation of packages like reshape and ggplot2, the latter of which has fundamentally changed the way many people think about data visualization. The chart below, displays the initial release date and number of downloads for seventeen of Hadley’s packages, but just barely scratches the surface of the impact of what has come to be dubbed the “Hadleyverse.”
The Early Days of Hadoop
Mike Cafarella Episode | O’Reilly Data Show Podcast
On the O’Reilly Data Show Podcast, Ben Lorica talks with Mike Cafarella, currently an assistant professor of computer science at the University of Michigan, but perhaps more famous for co-founding Hadoop and Nutch with Doug Cutting. Cafarella shares insights into his pioneering efforts on open source search and distributed systems, as well as a new startup, ClearCutAnalytics that developed out of a highly successful academic project on structured data extraction.
On the creation of the initial Hadoop Distributed File System (HDFS), Cafarella states:
We spent about a summer working on this distributed indexing mechanism…We finished it, and I felt pretty good about it, and then something like two hours later, we read the Google File System paper and realized, ‘Boy, actually that would be pretty handy; we could really use that.’ We threw out a chunk of it, implemented a very early version of the ideas in that paper, which we called HDFS.
Each week we surface, summarize, and share the most interesting stories and biggest news from the world of data science. Have articles or podcasts that you think we should be covering in our Data Science Roundup? Send them to editor@rjmetrics.com.
If you’re not signed up to receive the Data Science Roundup, subscribe here.
